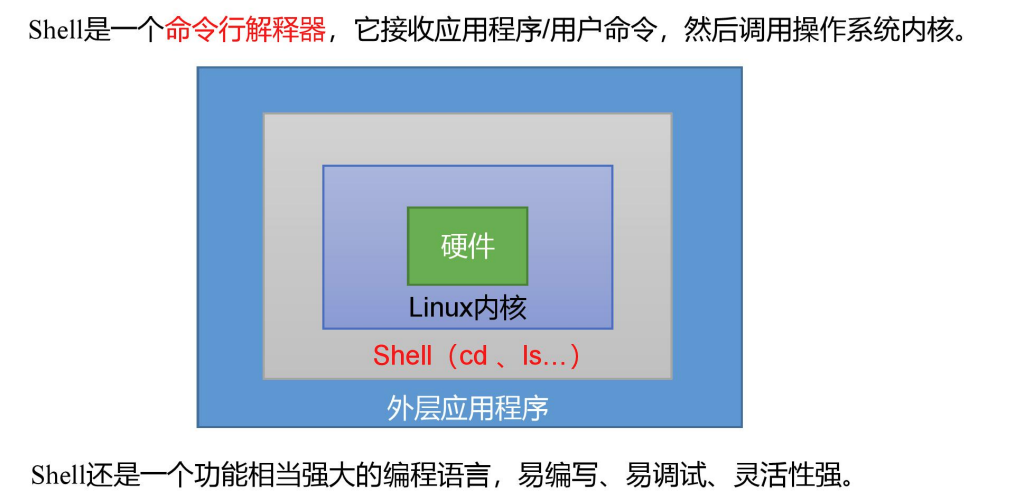
Shell
Shell 概述
1/bin/sh
2/bin/bash
3/usr/bin/sh
4/usr/bin/bash
5/bin/tcsh
6/bin/csh
1┌─[root@193_168_88_100] - [/bin] - [二 10月 25, 20:01]
2└─[$] <> ll | grep bash
3 bash
4 bashbug -> bashbug-64
5 bashbug-64
6 sh -> bash
1┌─[root@193_168_88_100] - [/bin] - [二 10月 25, 20:01]
2└─[$] <> echo $SHELL
3/bin/zsh
Shell 入门
脚本格式
第一个 Shell
脚本:helloworld.s
创建一个 Shell 脚本,输出 helloworld
1touch helloworld.sh
2vim helloworld.sh
在 helloworld.sh 中输入如下内容
1#!/bin/bash
2echo "helloworld"
脚本的常用执行方式
第一种
采用 bash 或 sh+脚本的相对路径或绝对路径(不用赋予脚本+x 权限) sh+脚本的相对路径
1sh ./helloworld.sh
2Helloworld
sh+脚本的绝对路径
1sh /home/atguigu/shells/helloworld.sh
2helloworld
bash+脚本的相对路径
1bash ./helloworld.sh
2Helloworld
bash+脚本的绝对路径
1bash /home/atguigu/shells/helloworld.sh
2Helloworld
第二种
采用输入脚本的绝对路径或相对路径执行脚本**(必须具有可执行权限+x)**
首先要赋予 helloworld.sh 脚本的+x 权限
执行脚本
相对路径
1./helloworld.sh
2Helloworld
绝对路径
1/home/atguigu/shells/helloworld.sh
2Helloworld
WARNING
注意:第一种执行方法,本质是 bash 解析器帮你执行脚本,所以脚本本身不需要执行 权限。第二种执行方法,本质是脚本需要自己执行,所以需要执行权限。
第三种
在脚本的路径前加上“.”或者 sourc
有以下脚本
1[atguigu@hadoop101 shells]$ cat test.sh
2#!/bin/bash
3A=5
4echo $A
分别使用 sh,bash,./ 和 . 的方式来执行,结果如下:
1[atguigu@hadoop101 shells]$ bash test.sh
2[atguigu@hadoop101 shells]$ echo $A
35
4[atguigu@hadoop101 shells]$ sh test.sh
5[atguigu@hadoop101 shells]$ echo $A
65
7[atguigu@hadoop101 shells]$ ./test.sh
8[atguigu@hadoop101 shells]$ echo $A
95
10[atguigu@hadoop101 shells]$ . test.sh
11[atguigu@hadoop101 shells]$ echo $A
125
原因:
- 前两种方式都是在当前
shell 中打开一个子 shell 来执行脚本内容,当脚本内容结束,则子 shell 关闭,回到父 shell 中。
- 第三种,也就是使用在脚本路径前加“.”或者
source 的方式,**可以使脚本内容在当前shell 里执行,而无需打开子 shell!**这也是为什么我们每次要修改完/etc/profile 文件以后,需要 source 一下的原因。
- 开子
shell 与不开子 shell 的区别就在于,环境变量的继承关系,如在子 shell 中设置的当前变量,父 shell 是不可见的
变量
系统预定义变量
常用系统变量 $HOME、$PWD、$SHELL、$USER...
1[atguigu@hadoop101 shells]$ echo $HOME
2/home/atguigu
1[atguigu@hadoop101 shells]$ set
2BASH=/bin/bash
3BASH_ALIASES=()
4BASH_ARGC=()
5BASH_ARGV=()
自定义变量
基本语法
- 定义变量:变量名=变量值,注意,=号前后不能有空格
- 撤销变量:unset 变量名
- 声明静态变量:readonly 变量,注意:不能 unset
变量定义规则
- 变量名称可以由字母、数字和下划线组成,但是不能以数字开头,环境变量名建议大写。
- 等号两侧不能有空格
- 在 bash 中,变量默认类型都是字符串类型,无法直接进行数值运算。
- 变量的值如果有空格,需要使用双引号或单引号括起来
案例实操
1[atguigu@hadoop101 shells]$ A=5
2[atguigu@hadoop101 shells]$ echo $A
35
1[atguigu@hadoop101 shells]$ A=8
2[atguigu@hadoop101 shells]$ echo $A
38
1[atguigu@hadoop101 shells]$ unset A
2[atguigu@hadoop101 shells]$ echo $A
1[atguigu@hadoop101 shells]$ readonly B=2
2[atguigu@hadoop101 shells]$ echo $B
32
4[atguigu@hadoop101 shells]$ B=9
5-bash: B: readonly variable
- 在 bash 中,变量默认类型都是字符串类型,无法直接进行数值运算
1[atguigu@hadoop102 ~]$ C=1+2
2[atguigu@hadoop102 ~]$ echo $C
31+2
1[atguigu@hadoop102 ~]$ D=I love banzhang
2-bash: world: command not found
3[atguigu@hadoop102 ~]$ D="I love banzhang"
4[atguigu@hadoop102 ~]$ echo $D
5I love banzhang
- 可把变量提升为全局环境变量,可供其他 Shell 程序使用,export 变量名
1[atguigu@hadoop101 shells]$ vim helloworld.sh
2
3# 在 helloworld.sh 文件中增加 echo $B
4
5#!/bin/bash
6echo "helloworld"
7echo $B
1[atguigu@hadoop101 shells]$ ./helloworld.sh
2Helloworld
发现并没有打印输出变量 B 的值。
1[atguigu@hadoop101 shells]$ export B
2[atguigu@hadoop101 shells]$ ./helloworld.sh
3helloworld
42
TIP
在子 Shell 中声明或者改变全局的变量都不会影响父 Shell 中的变量
字符串
字符串是 shell 编程中最常用最有用的数据类型(除了数字和字符串,也没啥其它类型好用了),字符串可以用单引号,也可以用双引号,也可以不用引号。
单引号
单引号字符串的限制:
- 单引号里的任何字符都会原样输出,单引号字符串中的变量是无效的;
- 单引号字串中不能出现单独一个的单引号(对单引号使用转义符后也不行),但可成对出现,作为字符串拼接使用。
双引号
1your_name="runoob"
2str="Hello, I know you are \"$your_name\"! \n"
3echo -e $str
双引号的优点:
数组
bash支持一维数组**(不支持多维数组),并且没有限定数组的大小**。
类似于 C 语言,数组元素的下标由 0 开始编号。获取数组中的元素要利用下标,下标可以是整数或算术表达式,其值应大于或等于 0。
定义数组
在 Shell 中,用括号来表示数组,数组元素用"空格"符号分割开。定义数组的一般形式为:
例如:
1array_name=(value0 value1 value2 value3)
或者
1array_name=(
2value0
3value1
4value2
5value3
6)
还可以单独定义数组的各个分量:
1array_name[0]=value0
2array_name[1]=value1
3array_name[n]=valuen
可以不使用连续的下标,而且下标的范围没有限制。
读取数组
读取数组元素值的一般格式是:
例如:
使用 @ 符号可以获取数组中的所有元素,例如:
获取数组的长度
获取数组长度的方法与获取字符串长度的方法相同,例如:
1*# 取得数组元素的个数*
2length=${#array_name[@]}
3*# 或者*
4length=${#array_name[*]}
5*# 取得数组单个元素的长度*
6lengthn=${#array_name[n]}
特殊变量
$n
功能描述:n 为数字,$0 代表该脚本名称,$1-$9 代表第一到第九个参数,十以上的参数,十以上的参数需要用大括号包含,如${10}
1[atguigu@hadoop101 shells]$ touch parameter.sh
2[atguigu@hadoop101 shells]$ vim parameter.sh
3#!/bin/bash
4echo '==========$n=========='
5echo $0
6echo $1
7echo $2
8[atguigu@hadoop101 shells]$ chmod 777 parameter.sh
9[atguigu@hadoop101 shells]$ ./parameter.sh cls xz
10==========$n==========
11./parameter.sh
12cls
13xz
$
功能描述:获取所有输入参数个数,常用于循环,判断参数的个数是否正确以及加强脚本的健壮性
1[atguigu@hadoop101 shells]$ vim parameter.sh
2#!/bin/bash
3echo '==========$n=========='
4echo $0
5echo $1
6echo $2
7echo '==========$#=========='
8echo $#
9[atguigu@hadoop101 shells]$ chmod 777 parameter.sh
10[atguigu@hadoop101 shells]$ ./parameter.sh cls xz
11==========$n==========
12./parameter.sh
13cls
14xz
15==========$#==========
162
$*、$@
$* 这个变量代表命令行中所有的参数,$*把所有的参数看成一个整体$@ 这个变量也代表命令行中所有的参数,不过$@把每个参数区分对待
1[atguigu@hadoop101 shells]$ vim parameter.sh
2#!/bin/bash
3echo '==========$n=========='
4echo $0
5echo $1
6echo $2
7echo '==========$#=========='
8echo $#
9echo '==========$*=========='
10echo $*
11echo '==========$@=========='
12echo $@
13[atguigu@hadoop101 shells]$ ./parameter.sh a b c d e f g
14==========$n==========
15./parameter.sh
16a
17b
18==========$#==========
197
20==========$*==========
21a b c d e f g
22==========$@==========
23a b c d e f
$?
$?最后一次执行的命令的返回状态。如果这个变量的值为 0,证明上一 个命令正确执行;如果这个变量的值为非 0(具体是哪个数,由命令自己来决定),则证明 上一个命令执行不正确了。
判断 helloworld.sh 脚本是否正确执
1[atguigu@hadoop101 shells]$ ./helloworld.sh
2hello world
3[atguigu@hadoop101 shells]$ echo $?
40
运算符
运算符有两种写法
((表达式))[ 表达式 ] 注意 [] 里面左右要有空格
算术运算符
下表列出了常用的算术运算符,假定变量 a 为 10,变量 b 为 20:
| 运算符 |
说明 |
举例 |
| + |
加法 |
expr $a + $b 结果为 30。 |
| - |
减法 |
expr $a - $b 结果为 -10。 |
| * |
乘法 |
expr $a \* $b 结果为 200。 |
| / |
除法 |
expr $b / $a 结果为 2。 |
| % |
取余 |
expr $b % $a 结果为 0。 |
| = |
赋值 |
a=$b 把变量 b 的值赋给 a。 |
| == |
相等。用于比较两个数字,相同则返回 true。 |
[ $a == $b ] 返回 false。 |
| != |
不相等。用于比较两个数字,不相同则返回 true。 |
[ $a != $b ] 返回 true。 |
**注意:**条件表达式要放在方括号之间,并且要有空格,例如: [$a==$b] 是错误的,必须写成 [ $a == $b ]。
1#!/bin/bash
2
3a=10
4b=20
5
6val=`expr $a + $b`
7echo "a + b : $val"
8
9val=`expr $a - $b`
10echo "a - b : $val"
11
12val=`expr $a \* $b`
13echo "a * b : $val"
14
15val=`expr $b / $a`
16echo "b / a : $val"
17
18val=`expr $b % $a`
19echo "b % a : $val"
20
21if [ $a == $b ]
22then
23 echo "a 等于 b"
24fi
25if [ $a != $b ]
26then
27 echo "a 不等于 b"
28fi
110 -eq 20: a 不等于 b
210 -ne 20: a 不等于 b
310 -gt 20: a 不大于 b
410 -lt 20: a 小于 b
510 -ge 20: a 小于 b
610 -le 20: a 小于或等于 b
TIP
- 乘号
(*)前边必须加反斜杠()才能实现乘法运算;
if...then...fi 是条件语句,后续将会讲解。- 在
MAC 中 shell 的 expr 语法是:$((表达式)),此处表达式中的 "*" 不需要转义符号 "" 。
关系运算符
关系运算符只支持数字,不支持字符串,除非字符串的值是数字。
下表列出了常用的关系运算符,假定变量 a 为 10,变量 b 为 20:
| 运算符 |
说明 |
举例 |
| -eq |
检测两个数是否相等,相等返回 true。 |
[ $a -eq $b ] 返回 false。 |
| -ne |
检测两个数是否不相等,不相等返回 true。 |
[ $a -ne $b ] 返回 true。 |
| -gt |
检测左边的数是否大于右边的,如果是,则返回 true。 |
[ $a -gt $b ] 返回 false。 |
| -lt |
检测左边的数是否小于右边的,如果是,则返回 true。 |
[ $a -lt $b ] 返回 true。 |
| -ge |
检测左边的数是否大于等于右边的,如果是,则返回 true。 |
[ $a -ge $b ] 返回 false。 |
| -le |
检测左边的数是否小于等于右边的,如果是,则返回 true。 |
[ $a -le $b ] 返回 true。 |
1#!/bin/bash
2
3a=10
4b=20
5
6if [ $a -eq $b ]
7then
8 echo "$a -eq $b : a 等于 b"
9else
10 echo "$a -eq $b: a 不等于 b"
11fi
12if [ $a -ne $b ]
13then
14 echo "$a -ne $b: a 不等于 b"
15else
16 echo "$a -ne $b : a 等于 b"
17fi
18if [ $a -gt $b ]
19then
20 echo "$a -gt $b: a 大于 b"
21else
22 echo "$a -gt $b: a 不大于 b"
23fi
24if [ $a -lt $b ]
25then
26 echo "$a -lt $b: a 小于 b"
27else
28 echo "$a -lt $b: a 不小于 b"
29fi
30if [ $a -ge $b ]
31then
32 echo "$a -ge $b: a 大于或等于 b"
33else
34 echo "$a -ge $b: a 小于 b"
35fi
36if [ $a -le $b ]
37then
38 echo "$a -le $b: a 小于或等于 b"
39else
40 echo "$a -le $b: a 大于 b"
41fi
110 != 20 : a 不等于 b
210 小于 100 且 20 大于 15 : 返回 true
310 小于 100 或 20 大于 100 : 返回 true
410 小于 5 或 20 大于 100 : 返回 false
TIP
这里我们使用 ((表达式)) 来做判断的话。在 ((表达式)) 中就可以写 <,>,<=,>=,=这些数学的运算符号
逻辑运算符
以下介绍 Shell 的逻辑运算符,假定变量 a 为 10,变量 b 为 20:
| 运算符 | 说明 | 举例 |
| ------ | ---------- | ------------------------------------------- | --------- | -------------- | --- | ------------------------ |
| && | 逻辑的 AND | [[$a -lt 100 && $b -gt 100]] 返回 false |
| | | | 逻辑的 OR | [[$a -lt 100 | | $b -gt 100]] 返回 true |
1!/bin/bash
2
3a=10
4b=20
5
6if [[ $a -lt 100 && $b -gt 100 ]]
7then
8 echo "返回 true"
9else
10 echo "返回 false"
11fi
12
13if [[ $a -lt 100 || $b -gt 100 ]]
14then
15 echo "返回 true"
16else
17 echo "返回 false"
18fi
字符串运算符
下表列出了常用的字符串运算符,假定变量 a 为 "abc",变量 b 为 "efg":
| 运算符 |
说明 |
举例 |
| = |
检测两个字符串是否相等,相等返回 true。 |
[ $a = $b ] 返回 false。 |
| != |
检测两个字符串是否不相等,不相等返回 true。 |
[ $a != $b ] 返回 true。 |
| -z |
检测字符串长度是否为 0,为 0 返回 true。 |
[ -z $a ] 返回 false。 |
| -n |
检测字符串长度是否不为 0,不为 0 返回 true。 |
[ -n "$a" ] 返回 true。 |
| $ |
检测字符串是否不为空,不为空返回 true。 |
[ $a ] 返回 true。 |
1#!/bin/bash
2
3a="abc"
4b="efg"
5
6if [ $a = $b ]
7then
8 echo "$a = $b : a 等于 b"
9else
10 echo "$a = $b: a 不等于 b"
11fi
12if [ $a != $b ]
13then
14 echo "$a != $b : a 不等于 b"
15else
16 echo "$a != $b: a 等于 b"
17fi
18if [ -z $a ]
19then
20 echo "-z $a : 字符串长度为 0"
21else
22 echo "-z $a : 字符串长度不为 0"
23fi
24if [ -n "$a" ]
25then
26 echo "-n $a : 字符串长度不为 0"
27else
28 echo "-n $a : 字符串长度为 0"
29fi
30if [ $a ]
31then
32 echo "$a : 字符串不为空"
33else
34 echo "$a : 字符串为空"
35fi
1abc = efg: a 不等于 b
2abc != efg : a 不等于 b
3-z abc : 字符串长度不为 0
4-n abc : 字符串长度不为 0
5abc : 字符串不为空
文件测试运算符
文件测试运算符用于检测 Unix 文件的各种属性。
属性检测描述如下:
| 操作符 |
说明 |
举例 |
| -b file |
检测文件是否是块设备文件,如果是,则返回 true。 |
[ -b $file ] 返回 false。 |
| -c file |
检测文件是否是字符设备文件,如果是,则返回 true。 |
[ -c $file ] 返回 false。 |
| -d file |
检测文件是否是目录,如果是,则返回 true。 |
[ -d $file ] 返回 false。 |
| -f file |
检测文件是否是普通文件(既不是目录,也不是设备文件),如果是,则返回 true。 |
[ -f $file ] 返回 true。 |
| -g file |
检测文件是否设置了 SGID 位,如果是,则返回 true。 |
[ -g $file ] 返回 false。 |
| -k file |
检测文件是否设置了粘着位(Sticky Bit),如果是,则返回 true。 |
[ -k $file ] 返回 false。 |
| -p file |
检测文件是否是有名管道,如果是,则返回 true。 |
[ -p $file ] 返回 false。 |
| -u file |
检测文件是否设置了 SUID 位,如果是,则返回 true。 |
[ -u $file ] 返回 false。 |
| -r file |
检测文件是否可读,如果是,则返回 true。 |
[ -r $file ] 返回 true。 |
| -w file |
检测文件是否可写,如果是,则返回 true。 |
[ -w $file ] 返回 true。 |
| -x file |
检测文件是否可执行,如果是,则返回 true。 |
[ -x $file ] 返回 true。 |
| -s file |
检测文件是否为空(文件大小是否大于 0),不为空返回 true。 |
[ -s $file ] 返回 true。 |
| -e file |
检测文件(包括目录)是否存在,如果是,则返回 true。 |
[ -e $file ] 返回 true。 |
其他检查符:
- -S: 判断某文件是否 socket。
- -L: 检测文件是否存在并且是一个符号链接。
1#!/bin/bash
2
3# 变量 file 表示文件 /var/www/runoob/test.sh,它的大小为 100 字节,具有 rwx 权限。下面的代码,将检测该文件的各种属性:
4file="/var/www/runoob/test.sh"
5if [ -r $file ]
6then
7 echo "文件可读"
8else
9 echo "文件不可读"
10fi
11if [ -w $file ]
12then
13 echo "文件可写"
14else
15 echo "文件不可写"
16fi
17if [ -x $file ]
18then
19 echo "文件可执行"
20else
21 echo "文件不可执行"
22fi
23if [ -f $file ]
24then
25 echo "文件为普通文件"
26else
27 echo "文件为特殊文件"
28fi
29if [ -d $file ]
30then
31 echo "文件是个目录"
32else
33 echo "文件不是个目录"
34fi
35if [ -s $file ]
36then
37 echo "文件不为空"
38else
39 echo "文件为空"
40fi
41if [ -e $file ]
42then
43 echo "文件存在"
44else
45 echo "文件不存在"
46fi
1文件可读
2文件可写
3文件可执行
4文件为普通文件
5文件不是个目录
6文件不为空
7文件存在
流程控制(重点)
if else
fi
if 语句语法格式:
1if condition
2then
3 command1
4 command2
5 ...
6 commandN
7fi
写成一行(适用于终端命令提示符):
1if [ $(ps -ef | grep -c "ssh") -gt 1 ]; then echo "true"; fi
TIP
末尾的 fi 就是 if 倒过来拼写,后面还会遇到类似的。
简单的说就是和JS中的 if() { } 这里的 {} 代表一个区域表示if成立了执行这个区域里面的代码,但在Shell中 {} 有这其他的含义,所以 if 代表开始 fi 代表结束把中间的代码框起来表示if成立后执行的代码。
其中 if 后的语句成功执行就会跳转到 then 后的语句,否则不跳转,then 表示判断成功后要执行的语句。
if else
if else 语法格式:
1if condition
2then
3 command1
4 command2
5 ...
6 commandN
7else
8 command
9fi
if else-if else
if else-if else 语法格式:
1if condition1
2then
3 command1
4elif condition2
5then
6 command2
7else
8 commandN
9fi
if else 的 [...] 判断语句中大于使用 -gt,小于使用 -lt。
1if [ "$a" -gt "$b" ]; then
2 ...
3fi
如果使用 ((...)) 作为判断语句,大于和小于可以直接使用 > 和 <。
1if (( a > b )); then
2 ...
3fi
以下实例判断两个变量是否相等:
1a=10
2b=20
3if [ $a == $b ]
4then
5 echo "a 等于 b"
6elif [ $a -gt $b ]
7then
8 echo "a 大于 b"
9elif [ $a -lt $b ]
10then
11 echo "a 小于 b"
12else
13 echo "没有符合的条件"
14fi
输出结果:
if else 语句经常与 test 命令结合使用,如下所示:
1num1=$[2*3]
2num2=$[1+5]
3if test $[num1] -eq $[num2]
4then
5 echo '两个数字相等!'
6else
7 echo '两个数字不相等!'
8fi
输出结果:
case ... esac
case ... esac 为多选择语句,与其他语言中的 switch ... case 语句类似,是一种多分支选择结构,每个 case 分支用右圆括号开始,用两个分号 ;; 表示 break,即执行结束,跳出整个 case ... esac 语句,esac(就是 case 反过来)作为结束标记。
可以用 case 语句匹配一个值与一个模式,如果匹配成功,执行相匹配的命令。
case ... esac 语法格式如下:
1case 值 in
2模式1)
3 command1
4 command2
5 ...
6 commandN
7 ;;
8模式2)
9 command1
10 command2
11 ...
12 commandN
13 ;;
14esac
case 工作方式如上所示,取值后面必须为单词 in,每一模式必须以右括号结束。取值可以为变量或常数,匹配发现取值符合某一模式后,其间所有命令开始执行直至 ;;。
取值将检测匹配的每一个模式。一旦模式匹配,则执行完匹配模式相应命令后不再继续其他模式。如果无一匹配模式,使用星号 * 捕获该值,再执行后面的命令。
下面的脚本提示输入 1 到 4,与每一种模式进行匹配:
1echo '输入 1 到 4 之间的数字:'
2echo '你输入的数字为:'
3read aNum
4case $aNum in
5 1) echo '你选择了 1'
6 ;;
7 2) echo '你选择了 2'
8 ;;
9 3) echo '你选择了 3'
10 ;;
11 4) echo '你选择了 4'
12 ;;
13 *) echo '你没有输入 1 到 4 之间的数字'
14 ;;
15esac
输入不同的内容,会有不同的结果,例如:
1输入 1 到 4 之间的数字:
2你输入的数字为:
33
4你选择了 3
for 循环
与其他编程语言类似,Shell支持for循环。
写法一
for循环一般格式为
1for var in item1 item2 ... itemN
2do
3 command1
4 command2
5 ...
6 commandN
7done
写成一行:
1for var in item1 item2 ... itemN; do command1; command2… done;
TIP
这里 do 和 done 就和 { } 一样来确定范围
当变量值在列表里,for 循环即执行一次所有命令,使用变量名获取列表中的当前取值。命令可为任何有效的 shell 命令和语句。in 列表可以包含替换、字符串和文件名。
in列表是可选的,如果不用它,for 循环使用命令行的位置参数。
例如,顺序输出当前列表中的数字:
1for loop in 1 2 3 4 5
2do
3 echo "The value is: $loop"
4done
输出结果:
1The value is: 1
2The value is: 2
3The value is: 3
4The value is: 4
5The value is: 5
顺序输出字符串中的字符:
1#!/bin/bash
2
3for str in This is a string
4do
5 echo $str
6done
输出结果:
写法二
1for (( 初始值;循环控制条件;变量变化 ))
2do
3程序
4done
从 1 加到 100 ,for1.sh
1#!/bin/bash
2sum=0
3for((i=0;i<=100;i++))
4do
5sum=$[$sum+$i]
6done
7echo $sum
1[atguigu@hadoop101 shells]$ chmod 777 for1.sh
2[atguigu@hadoop101 shells]$ ./for1.sh
35050
while 语句
while 循环用于不断执行一系列命令,也用于从输入文件中读取数据。其语法格式为:
1while condition
2do
3 command
4done
以下是一个基本的 while 循环,测试条件是:如果 int 小于等于 5,那么条件返回真。int 从 1 开始,每次循环处理时,int 加 1。运行上述脚本,返回数字 1 到 5,然后终止。
1#!/bin/bash
2int=1
3while(( $int<=5 ))
4do
5 echo $int
6 let "int++"
7done
运行脚本,输出:
以上实例使用了 Bash let 命令,它用于执行一个或多个表达式,变量计算中不需要加上 $ 来表示变量,具体可查阅:Bash let 命令 open in new window。
while循环可用于读取键盘信息。下面的例子中,输入信息被设置为变量FILM,按<Ctrl-D>结束循环。
1echo '按下 <CTRL-D> 退出'
2echo -n '输入你最喜欢的网站名: '
3while read FILM
4do
5 echo "是的!$FILM 是一个好网站"
6done
无限循环
无限循环语法格式:
或者
1while true
2do
3 command
4done
或者
until 循环
until 循环执行一系列命令直至条件为 true 时停止。
until 循环与 while 循环在处理方式上刚好相反。
一般 while 循环优于 until 循环,但在某些时候—也只是极少数情况下,until 循环更加有用。
until 语法格式:
1until condition
2do
3 command
4done
condition 一般为条件表达式,如果返回值为 false,则继续执行循环体内的语句,否则跳出循环。
以下实例我们使用 until 命令来输出 0 ~ 9 的数字:
1#!/bin/bash
2
3a=0
4
5until [ ! $a -lt 10 ]
6do
7 echo $a
8 a=`expr $a + 1`
9done
输出结果为:
跳出循环
在循环过程中,有时候需要在未达到循环结束条件时强制跳出循环,Shell 使用两个命令来实现该功能:break 和 continue。
break 命令
break 命令允许跳出所有循环(终止执行后面的所有循环)。
下面的例子中,脚本进入死循环直至用户输入数字大于 5。要跳出这个循环,返回到 shell 提示符下,需要使用 break 命令。
1#!/bin/bash
2while :
3do
4 echo -n "输入 1 到 5 之间的数字:"
5 read aNum
6 case $aNum in
7 1|2|3|4|5) echo "你输入的数字为 $aNum!"
8 ;;
9 *) echo "你输入的数字不是 1 到 5 之间的! 游戏结束"
10 break
11 ;;
12 esac
13done
执行以上代码,输出结果为:
1输入 1 到 5 之间的数字:3
2你输入的数字为 3!
3输入 1 到 5 之间的数字:7
4你输入的数字不是 1 到 5 之间的! 游戏结束
continue
continue 命令与 break 命令类似,只有一点差别,它不会跳出所有循环,仅仅跳出当前循环。
对上面的例子进行修改:
1#!/bin/bash
2while :
3do
4 echo -n "输入 1 到 5 之间的数字: "
5 read aNum
6 case $aNum in
7 1|2|3|4|5) echo "你输入的数字为 $aNum!"
8 ;;
9 *) echo "你输入的数字不是 1 到 5 之间的!"
10 continue
11 echo "游戏结束"
12 ;;
13 esac
14done
运行代码发现,当输入大于 5 的数字时,该例中的循环不会结束,语句 echo "游戏结束" 永远不会被执行。
函数
函数定义
linux shell 可以用户定义函数,然后在 shell 脚本中可以随便调用。
shell中函数的定义格式如下:
1[ function ] funname [()]
2
3{
4
5 action;
6
7 [return int;]
8
9}
说明:
- 1、可以带
function fun() 定义,也可以直接fun() 定义,不带任何参数。
- 2、参数返回,可以显示加:
return 返回,如果不加,将以最后一条命令运行结果,作为返回值。 return后跟数值n(0-255)
下面的例子定义了一个函数并进行调用:
1#!/bin/bash
2
3demoFun(){
4 echo "这是我的第一个 shell 函数!"
5}
6echo "-----函数开始执行-----"
7demoFun
8echo "-----函数执行完毕-----"
输出结果:
1-----函数开始执行-----
2这是我的第一个 shell 函数!
3-----函数执行完毕-----
下面定义一个带有return语句的函数:
1#!/bin/bash
2
3funWithReturn(){
4 echo "这个函数会对输入的两个数字进行相加运算..."
5 echo "输入第一个数字: "
6 read aNum
7 echo "输入第二个数字: "
8 read anotherNum
9 echo "两个数字分别为 $aNum 和 $anotherNum !"
10 return $(($aNum+$anotherNum))
11}
12funWithReturn
13echo "输入的两个数字之和为 $? !"
输出类似下面:
1这个函数会对输入的两个数字进行相加运算...
2输入第一个数字:
31
4输入第二个数字:
52
6两个数字分别为 1 和 2 !
7输入的两个数字之和为 3 !
函数返回值在调用该函数后通过 $? 来获得。
TIP
注意:所有函数在使用前必须定义。这意味着必须将函数放在脚本开始部分,直至shell解释器首次发现它时,才可以使用。调用函数仅使用其函数名即可。
函数参数
在Shell中,调用函数时可以向其传递参数。在函数体内部,通过 $n 的形式来获取参数的值,例如,$1表示第一个参数,$2 表示第二个参数...
带参数的函数示例:
1#!/bin/bash
2
3funWithParam(){
4 echo "第一个参数为 $1 !"
5 echo "第二个参数为 $2 !"
6 echo "第十个参数为 $10 !"
7 echo "第十个参数为 ${10} !"
8 echo "第十一个参数为 ${11} !"
9 echo "参数总数有 $# 个!"
10 echo "作为一个字符串输出所有参数 $* !"
11}
12funWithParam 1 2 3 4 5 6 7 8 9 34 73
输出结果:
1第一个参数为 1 !
2第二个参数为 2 !
3第十个参数为 10 !
4第十个参数为 34 !
5第十一个参数为 73 !
6参数总数有 11 个!
7作为一个字符串输出所有参数 1 2 3 4 5 6 7 8 9 34 73 !
TIP
注意,$10 不能获取第十个参数,获取第十个参数需要${10}。当n>=10时,需要使用${n}来获取参数。
另外,还有几个特殊字符用来处理参数:
| 参数处理 |
说明 |
| $# |
传递到脚本或函数的参数个数 |
| $* |
以一个单字符串显示所有向脚本传递的参数 |
| $$ |
脚本运行的当前进程 ID 号 |
| $! |
后台运行的最后一个进程的 ID 号 |
| $@ |
与$*相同,但是使用时加引号,并在引号中返回每个参数。 |
| $- |
显示 Shell 使用的当前选项,与 set 命令功能相同。 |
| $? |
显示最后命令的退出状态。0 表示没有错误,其他任何值表明有错误。 |
获取函数的返回值
1#!/bin/bash
2
3getsum(){
4 local sum=0 #局部变量
5 for((i=$1; i<=$2; i++)); do
6 ((sum+=i))
7 done
8 echo $sum
9 return $? # 这里$?就是 echo $sum 执行的结果
10}
11read m
12read n
13total=$(getsum $m $n)
14echo "The sum is $total"
TIP
函数没有return的时候返回值是最后一行代码的执行结果。
正侧表达式
基本正侧表达式
正则表达式和通配符的区别:
- 正则表达式用来在文件中匹配符合条件的字符串,正则是包含匹配.
grep、awk、sed 等命令可以支持正则表达式。
- 通配符
( ?[])是用来匹配符合条件的文件名*,通配符是完全匹配。ls、find、cp 等命令不支持正则表达式,所有只能使用 shell 自己的通配符来进行匹配了。
| 元字符 |
作用 |
* |
前一个字符匹配 0 次或者任意多次 |
. |
匹配除了换行符外任意一个字符 |
^ |
匹配行首, |
例如:^hello会匹配以hello开头的行。 |
|
$ |
匹配行首, |
例如:hello$会匹配以hello开头的行。 |
|
[ ] |
匹配括号中指定的任意一个字符,只匹配一个字符 |
[ ^] |
匹配除中括号的字符意外的任意一个字符。 |
例如:[^0-9]匹配任意一个非数字字符。 |
|
\ |
转义符。用于将特殊符号的含义取消 |
{n} |
表示其前面的字符签好出现 n 次。 |
例如:[0-9]{4}匹配 4 位数字,[1][3-8][0-9]{9} 匹配手机号码 |
|
{n,} |
表示七千亩的字符出现不小于 n 次。 |
例如:[0-9]{2,}表示两位及以上的数字 |
|
{n,m} |
表示其前面的字符至少出现 n 次,最多出现 m 次。 |
例如:[a-z]{6,8}匹配 6 到 8 为的小写子母。 |
|
1grep "a*" test_rule.txt
2#匹配所有内容,包括空白行
3grep "aaaa*" test_rule.txt
4#匹配最少包含三个连续a的字符串
5grep "s..d" test_rule.txt
6#匹配在s和d两个子母之间的有两个字符的单词
7grep "s.*d" test_rule.txt
8#匹配在s和d之间有任意字符的单词所在的行
9grep "^M" test_rule.txt
10#匹配以大写子母M开头的行
11grep "n$" test_rule.txt
12#匹配以小写n结尾的行
13grep -n "^$" test_rule.txt
14#匹配空白行
15grep "^[a-z]" test_rule.txt
16#匹配以小写子母开头的行
17grep "\.$" test_rule.txt
18#匹配以.结尾的行
常用正侧表达式
| 字符 | 描述 |
| --- | --- | --- | --- |
| \ | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符。 |
| 例如:“n”匹配字符“n”。“\n”匹配一个换行符。序列“\\”匹配“\”而“\(”则匹配“(”。 |
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^也匹配“\n”或“\r”之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了 RegExp 对象的 Multiline 属性,$也匹配“\n”或“\r”之前的位置。 |
| * | 匹配前面的子表达式零次或多次。 |
| 例如:zo*能匹配“z”以及“zoo”。*等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。 |
| 例如:“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 |
| ? | 匹配前面的子表达式零次或一次。 |
| 例如:“do(es)?”可以匹配“do”或“does”中的“do”。?等价于{0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。 |
| 例如:“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配 n 次。 |
| 例如:“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有 o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 |
| {n,m} | m 和 n 均为非负整数,其中 n<=m。最少匹配 n 次且最多匹配 m 次。 |
| 例如:“o{1,3}”将匹配“fooooood”中的前三个 o。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。 |
| 例如:对于字符串“oooo”,“o+?”将匹配单个“o”,而“o+”将匹配所有“o”。 |
| . | 匹配除“\n”之外的任何单个字符。要匹配包括“\n”在内的任何字符,请使用像“[.\n]”的模式。 |
| (pattern) | 匹配 pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在 VBScript 中使用 SubMatches 集合,在 JScript 中则使用$0…$9 属性。要匹配圆括号字符,请使用“”或“”或“”。 |
| (?:pattern) | 匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用或字符“( | )”来组合一个模式的各个部分是很有用。 |
| 例如“industr(?:y | ies)”就是一个比“industry | industries”更简略的表达式。 |
| (?=pattern) | 正向预查,在任何匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。 |
| 例如:“Windows(?=95 | 98 | NT | 2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!pattern) | 负向预查,在任何不匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。 |
| 例如“Windows(?!95 | 98 | NT | 2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始 |
| x | y | 匹配 x 或 y。 |
| 例如:“z | food”能匹配“z”或“food”。“(z | f)ood”则匹配“zood”或“food”。 |
| [xyz] | 字符集合。匹配所包含的任意一个字符。 |
| 例如:“[abc]”可以匹配“plain”中的“a”。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。 |
| 例如:“[^abc]”可以匹配“plain”中的“p”。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。 |
| 例如:“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。 |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。 |
| 例如:“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。 |
| 例如:“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。 |
| \B | 匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。 |
| \cx | 匹配由 x 指明的控制字符。 |
| 例如:\cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的“c”字符。 |
| \d | 匹配一个数字字符。等价于[0-9]。 |
| \D | 匹配一个非数字字符。等价于[^0-9]。 |
| \f | 匹配一个换页符。等价于\x0c 和\cL。 |
| \n | 匹配一个换行符。等价于\x0a 和\cJ。 |
| \r | 匹配一个回车符。等价于\x0d 和\cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[\f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于[^\f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于\x09 和\cI。 |
| \v | 匹配一个垂直制表符。等价于\x0b 和\cK。 |
| \w | 匹配包括下划线的任何单词字符。等价于“[A-Za-z0-9_]”。 |
| \W | 匹配任何非单词字符。等价于“[^a-za-z0-9_]”。 |
| \xn | 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。 |
| 例如:“\x41”匹配“A”。“\x041”则等价于“\x04&1”。正则表达式中可以使用 ASCII 编码。. |
| \num | 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。 |
| 例如:“(.)\1”匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个向后引用。如果\n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字(0-7),则 n 为一个八进制转义值。 |
| \nm | 标识一个八进制转义值或一个向后引用。如果\nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果\nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字(0-7),则\nm 将匹配八进制转义值 nm。 |
| \nml | 如果 n 为八进制数字(0-3),且 m 和 l 均为八进制数字(0-7),则匹配八进制转义值 nml。 |
| \un | 匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。 |
| 例如:\u00A9 匹配版权符号(?)。 |
文本处理工具
cut 命令
语法
1cut [-bn] [file]
2cut [-c] [file]
3cut [-df] [file]
使用说明:
cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。
如果不指定 File 参数,cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一。
参数:
- -b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。
- -c :以字符为单位进行分割。
- -d :自定义分隔符,默认为制表符。
- -f :与-d 一起使用,指定显示哪个区域。
- -n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的 范围之内,该字符将被写出;否则,该字符将被排除
实例
当你执行 who 命令时,会输出类似如下的内容:
1$ who
2rocrocket :0 2009-01-08 11:07
3rocrocket pts/0 2009-01-08 11:23 (:0.0)
4rocrocket pts/1 2009-01-08 14:15 (:0.0)
如果我们想提取每一行的第 3 个字节,就这样:
awk 命令
语法
1awk [选项参数] 'script' var=value file(s)
2或
3awk [选项参数] -f scriptfile var=value file(s)
选项参数说明:
-F fs or --field-separator fs 指定输入文件折分隔符,fs 是一个字符串或者是一个正则表达式,如-F:。-v var=value or --asign var=value 赋值一个用户定义变量。-f scripfile or --file scriptfile 从脚本文件中读取awk命令。-mf nnn and -mr nnn 对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是 Bell 实验室版awk的扩展功能,在标准awk中不适用。-W compact or --compat, -W traditional or --traditional 在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。-W copyleft or --copyleft, -W copyright or --copyright 打印简短的版权信息。-W help or --help, -W usage or --usage 打印全部awk选项和每个选项的简短说明。-W lint or --lint 打印不能向传统unix平台移植的结构的警告。-W lint-old or --lint-old 打印关于不能向传统unix平台移植的结构的警告。-W posix 打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符和=不能代替^和^=;fflush无效。-W re-interval or --re-inerval 允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。-W source program-text or --source program-text 使用 program-text作为源代码,可与-f 命令混用。-W version or --version 打印 bug 报告信息的版本。
基本用法
log.txt 文本内容如下:
12 this is a test
23 Do you like awk
3This's a test
410 There are orange,apple,mongo
用法一:
1awk '{[pattern] action}' {filenames} # 行匹配语句 awk '' 只能用单引号
实例:
1# 每行按空格或TAB分割,输出文本中的1、4项
2 $ awk '{print $1,$4}' log.txt
3 ---------------------------------------------
4 2 a
5 3 like
6 This's
7 10 orange,apple,mongo
8 # 格式化输出
9 $ awk '{printf "%-8s %-10s\n",$1,$4}' log.txt
10 ---------------------------------------------
11 2 a
12 3 like
13 This's
14 10 orange,apple,mongo
用法二:
1awk -F #-F相当于内置变量FS, 指定分割字符
实例:
1# 使用","分割
2 $ awk -F, '{print $1,$2}' log.txt
3 ---------------------------------------------
4 2 this is a test
5 3 Do you like awk
6 This's a test
7 10 There are orange apple
8 # 或者使用内建变量
9 $ awk 'BEGIN{FS=","} {print $1,$2}' log.txt
10 ---------------------------------------------
11 2 this is a test
12 3 Do you like awk
13 This's a test
14 10 There are orange apple
15 # 使用多个分隔符.先使用空格分割,然后对分割结果再使用","分割
16 $ awk -F '[ ,]' '{print $1,$2,$5}' log.txt
17 ---------------------------------------------
18 2 this test
19 3 Are awk
20 This's a
21 10 There apple
用法三:
实例:
1$ awk -va=1 '{print $1,$1+a}' log.txt
2 ---------------------------------------------
3 2 3
4 3 4
5 This's 1
6 10 11
7 $ awk -va=1 -vb=s '{print $1,$1+a,$1b}' log.txt
8 ---------------------------------------------
9 2 3 2s
10 3 4 3s
11 This's 1 This'ss
12 10 11 10s
用法四:
实例:
运算符
| 运算符 | 描述 |
| --------------------------- | -------------------------------- | --- | ------ |
| = += -= *= /= %= ^= **= | 赋值 |
| ?: | C 条件表达式 |
| | | | 逻辑或 |
| && | 逻辑与 |
| ~ 和 !~ | 匹配正则表达式和不匹配正则表达式 |
| < <= > >= != == | 关系运算符 |
| 空格 | 连接 |
| + - | 加,减 |
| * / % | 乘,除与求余 |
| + - ! | 一元加,减和逻辑非 |
| ^ *** | 求幂 |
| ++ -- | 增加或减少,作为前缀或后缀 |
| $ | 字段引用 |
| in | 数组成员 |
过滤第一列大于 2 的行
1$ awk '$1>2' log.txt #命令
2#输出
33 Do you like awk
4This's a test
510 There are orange,apple,mongo
过滤第一列等于 2 的行
1$ awk '$1==2 {print $1,$3}' log.txt #命令
2#输出
32 is
过滤第一列大于 2 并且第二列等于'Are'的行
1$ awk '$1>2 && $2=="Are" {print $1,$2,$3}' log.txt #命令
2#输出
33 Are you
内建变量
| 变量 |
描述 |
$n |
当前记录的第 n 个字段,字段间由FS分隔 |
$0 |
完整的输入记录 |
ARGC |
命令行参数的数目 |
ARGIND |
命令行中当前文件的位置(从 0 开始算) |
ARGV |
包含命令行参数的数组 |
CONVFMT |
数字转换格式(默认值为%.6g)ENVIRON环境变量关联数组 |
ERRNO |
最后一个系统错误的描述 |
FIELDWIDTHS |
字段宽度列表(用空格键分隔) |
FILENAME |
当前文件名 |
FNR |
各文件分别计数的行号 |
FS |
字段分隔符(默认是任何空格) |
IGNORECASE |
如果为真,则进行忽略大小写的匹配 |
NF |
一条记录的字段的数目 |
NR |
已经读出的记录数,就是行号,从 1 开始 |
OFMT |
数字的输出格式(默认值是%.6g) |
OFS |
输出字段分隔符,默认值与输入字段分隔符一致。 |
ORS |
输出记录分隔符(默认值是一个换行符) |
RLENGTH |
由match函数所匹配的字符串的长度 |
RS |
记录分隔符(默认是一个换行符) |
RSTART |
由match函数所匹配的字符串的第一个位置 |
SUBSEP |
数组下标分隔符(默认值是/034) |
1$ awk 'BEGIN{printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n","FILENAME","ARGC","FNR","FS","NF","NR","OFS","ORS","RS";printf "---------------------------------------------\n"} {printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n",FILENAME,ARGC,FNR,FS,NF,NR,OFS,ORS,RS}' log.txt
2FILENAME ARGC FNR FS NF NR OFS ORS RS
3---------------------------------------------
4log.txt 2 1 5 1
5log.txt 2 2 5 2
6log.txt 2 3 3 3
7log.txt 2 4 4 4
8$ awk -F\' 'BEGIN{printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n","FILENAME","ARGC","FNR","FS","NF","NR","OFS","ORS","RS";printf "---------------------------------------------\n"} {printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n",FILENAME,ARGC,FNR,FS,NF,NR,OFS,ORS,RS}' log.txt
9FILENAME ARGC FNR FS NF NR OFS ORS RS
10---------------------------------------------
11log.txt 2 1 ' 1 1
12log.txt 2 2 ' 1 2
13log.txt 2 3 ' 2 3
14log.txt 2 4 ' 1 4
15# 输出顺序号 NR, 匹配文本行号
16$ awk '{print NR,FNR,$1,$2,$3}' log.txt
17---------------------------------------------
181 1 2 this is
192 2 3 Are you
203 3 This's a test
214 4 10 There are
22# 指定输出分割符
23$ awk '{print $1,$2,$5}' OFS=" $ " log.txt
24---------------------------------------------
252 $ this $ test
263 $ Are $ awk
27This's $ a $
2810 $ There $
使用正则,字符串匹配
1# 输出第二列包含 "th",并打印第二列与第四列
2$ awk '$2 ~ /th/ {print $2,$4}' log.txt
3---------------------------------------------
4this a
~ 表示模式开始。// 中是模式。
1# 输出包含 "re" 的行
2$ awk '/re/ ' log.txt
3---------------------------------------------
43 Do you like awk
510 There are orange,apple,mongo
忽略大小写
1$ awk 'BEGIN{IGNORECASE=1} /this/' log.txt
2---------------------------------------------
32 this is a test
4This's a test
模式取反
1$ awk '$2 !~ /th/ {print $2,$4}' log.txt
2---------------------------------------------
3Are like
4a
5There orange,apple,mongo
6$ awk '!/th/ {print $2,$4}' log.txt
7---------------------------------------------
8Are like
9a
10There orange,apple,mongo
awk 脚本
关于 awk 脚本,我们需要注意两个关键词 BEGIN 和 END。
- BEGIN{ 这里面放的是执行前的语句 }
- END {这里面放的是处理完所有的行后要执行的语句 }
- {这里面放的是处理每一行时要执行的语句}
假设有这么一个文件(学生成绩表):
1$ cat score.txt
2Marry 2143 78 84 77
3Jack 2321 66 78 45
4Tom 2122 48 77 71
5Mike 2537 87 97 95
6Bob 2415 40 57 62
我们的 awk 脚本如下:
1$ cat cal.awk
2#!/bin/awk -f
3#运行前
4BEGIN {
5 math = 0
6 english = 0
7 computer = 0
8
9 printf "NAME NO. MATH ENGLISH COMPUTER TOTAL\n"
10 printf "---------------------------------------------\n"
11}
12#运行中
13{
14 math+=$3
15 english+=$4
16 computer+=$5
17 printf "%-6s %-6s %4d %8d %8d %8d\n", $1, $2, $3,$4,$5, $3+$4+$5
18}
19#运行后
20END {
21 printf "---------------------------------------------\n"
22 printf " TOTAL:%10d %8d %8d \n", math, english, computer
23 printf "AVERAGE:%10.2f %8.2f %8.2f\n", math/NR, english/NR, computer/NR
24}
我们来看一下执行结果:
1$ awk -f cal.awk score.txt
2NAME NO. MATH ENGLISH COMPUTER TOTAL
3---------------------------------------------
4Marry 2143 78 84 77 239
5Jack 2321 66 78 45 189
6Tom 2122 48 77 71 196
7Mike 2537 87 97 95 279
8Bob 2415 40 57 62 159
9---------------------------------------------
10 TOTAL: 319 393 350
11AVERAGE: 63.80 78.60 70.00
另外一些实例
AWK 的 hello world 程序为:
1BEGIN { print "Hello, world!" }
计算文件大小
1$ ls -l *.txt | awk '{sum+=$5} END {print sum}'
2--------------------------------------------------
3666581
从文件中找出长度大于 80 的行:
打印九九乘法表
1seq 9 | sed 'H;g' | awk -v RS='' '{for(i=1;i<=NF;i++)printf("%dx%d=%d%s", i, NR, i*NR, i==NR?"\n":"\t")}'
发送消息案例
1#!/bin/zsh
2
3# 查看用户是否登录
4login_user=$(who | grep -i -m 1 $1 | awk '{ print $1}')
5
6if [ -z $login_user ]
7then
8 echo "$1 不在线"
9 echo “脚本退出”
10 exit
11fi
12
13# 查看用户是否开启了消息功能
14is_allowwed=$(who | grep -i -m 1 $1 | awk '{ print $1}')
15
16if [ $is_allowwed != '+' ]
17then
18 echo "$1 没有开启消息功能"
19 echo “脚本退出”
20 exit
21fi
22
23# 确认是否消息发送
24if [ -z $2 ]
25then
26 echo "没有消息发送"
27 echo “脚本退出”
28 exit
29fi
30
31# 从参数中获取要发送的消息
32whole_msg=$(echo $* | cut -d " " -f 2-)
33
34# 获取用户登录的终端
35user_terminal=$(who | grep -i -m 1 $1 | awk '{print $2}')
36
37# 写入发送的消息
38echo $whole_msg | write $login_user $user_terminal
39
40if [ $? != 0 ]
41then
42 echo "发送失败“
43else
44 echo "发送成功"
45fi
46exit